デザインパターンの軽いまとめ
記事を書く背景
コーディングの設計について考えることがあり、デザインパターンを改めて勉強したくなったためです。
書きたいコードのイメージに対して「デザインパターンのあれを使えば良いのでは?」と思い出せるように各デザインパターンの考え方や概要を自分用のメモとして残しておく目的です。
Java言語で学ぶデザインパターン入門第3版
を参考にしながら書きました。
ちょこちょこChatGPT相手に壁打ちしたので、それのリンクも載せています。
各デザインパターン
①Iterator
独自のデータ構造や特定の反復処理が必要な場合、カスタムのイテレータを検討したいときに参考にするかもしないパターン。
イテラブルなオブジェクトとかインターフェースで問題ないなら、ほとんど自分で実装することはないと思われる。
②Adapter
既存のクラスやデータを、新しいAPIやインターフェースで使えるようにしたい場合などに有用。
既に存在していたコードを変更することなくAPIを実行できるため、テストするのはAPIに渡すアダプター部分のコードだけで済む。
③Template Method
処理の順番は決めておきたいが、具体的な処理は場合によって分けたいときに検討するパターン。
例えば、
①外部データをインプット
②インプットしたデータを成形
③成形したデータを何らかの手段で保存
という処理をしたい場合に、①でどこからインプットする、②でどのように成形する、③どこにどう保存するというのをケースに分けて実装する。
しかし、上記のフロー自体は親のクラスに定義しておくことで、継承したクラスでは具体的な処理を実装すれば良いことになる。
④Factory Method
Tempate Methodの考え方をインスタンス生成に適用するパターン。
Productという抽象クラスと、おなじく抽象的なFactoryクラスを用意して、それぞれに対応させる形で具体的なクラスを実装する。
複数のProductを生成し、Product毎でのふるまいは似ているがちょっと違う、というときに使う。
Productにuse()という抽象メソッドを定義し、継承した具体クラスではuse()を実装すればProduct毎に異なる処理をさせることができる。
FactoryクラスからProductクラスを作成する処理を定義するため、FactoryとProductを継承した具体クラスは1 : 1の関係になる。
⑤Singleton
実行しているプログラム内で、インスタンスが絶対に1つしかないことを保証したいときに使うパターン。
DBへの接続情報や、ログの設定管理など全体で共通の情報はSingletonパターンの考え方で一つのインスタンスが作成できれば問題ないため、使われることがある。
⑥Prototype
インスタンスの生成コストを抑えるために、既存のインスタンスをコピーして新しいインスタンスを作成するときに有用なパターン。
例として、ゲームなどで同じ敵を大量生産するときに、Pythonだったらcopyモジュールを使って全く同じ中身の別のインスタンスを生成したりする。
⑦Builder
複雑な設定付きのオブジェクトを条件によって複数種類、かつ段階的に構築したいときなどに使うパターン。
Director、Builder、Builderを継承した具体Builderの3クラスで使う。
Directorは抽象クラスのBuilderしか知らず、Builderに対して指示を出すが実際の処理は具体Builderで行う。
やや使いどころがイメージしずらく、特にFactory Methodとの使い分けがむずかしい
chatGPTいわく、
🔧 「何を作るかが変わる」なら → Factory Method
🏗️ 「どう作るか(構成・順番)が複雑」なら → Builder
 ※これもchatGPTから
※これもchatGPTから
ChatGPT - Factory vs Builderパターン
⑧Abstract Factory
以下のQiitaのまとめがわかりやすかった。
- 直訳では「抽象的な工場」ですが、いろんな部品を組み合わせて一つの製品を作るときに有効なパターンで、部品は固定であるときが有効
- 逆にいちいち部品が変わる場合は使わない方が良い qiita.com
例えばvscodeをWindows向けとMac向けなどで作る場合、vscodeとしての部品は変わらないため有用かもしれない。
ただ、Webアプリを作る場合にはあまり使わなさそう。
⑨Bridge
とある機能に対して、表現方法を複数指定するような設計で有用。
参考書籍では以下のクラスが例として紹介されている。
- 機能のクラス:Displayクラス(抽象)とCountDisplay(具体)
- 実装のクラス:DisplayImplクラス(抽象)とStringDisplayImpl(具体)
StringDisplayImplはSystem.out.println()に対して結果の出力をさせているが、HtmlDisplayImplというクラスを追加し、Displayインスタンス生成時にHtmlDisplayImplインスタンスを渡せた、HTMLでの結果表示をさせることができる。
もちろん、結果表示のための実装はHtmlDisplayImpl内で行う必要がある。
⑩Strategy
Strategyパターンの肝はこの一文だと思う。
同じ問題を別の方法で解くのを容易にする
書籍ではじゃんけんで勝つための戦略をStrategyクラス(抽象)で定義し、具体的な戦略をStrategyクラスを継承したクラスで実装している。
 個人的にはStrategyが委譲されているクラスがContextという命名がとてもわかりやすかった。
個人的にはStrategyが委譲されているクラスがContextという命名がとてもわかりやすかった。
Contextクラスがつまり、「同じ問題」であり、それを解く方法が各Strategyということだと理解した。
別の書籍だが「良いコード/悪いコードで学ぶ設計入門 ―保守しやすい 成長し続けるコードの書き方」では「敵にダメージを与える方法」をStrategyクラスとして定義している。
⑪Composite
入れ物と中身を同一視して、オブジェクトを入れ子構造にしたい場合に有用なパターン。
わかりやすい例で言うとGUIでウィンドウを作り、その中にさらにパネルやボタンを追加するなど。
また、ファイルとフォルダのような関係の物だったら表現しやすい。
⑫Decorator
Compositeパターンと似て非なるもの。
単純な機能に対して、機能拡充させるような使い方をする。
そのために共通のインターフェースに対して実装して必要に応じて機能を追加して実装する。

⑬Visitor
VisitorはElementの内部構造には立ち入らず、Elementが提供するインターフェースを通じてデータを受け取り、独自の処理をするのが特徴のデザインパターン。 整理するためのにchatGPTとのやりとりはこちら。 ChatGPT - Visitorパターンの理解
⑭Chain of Responsibility
データが渡されてからどんな処理をさせたいかを動的に決定するためのパターン。
VisitorパターンではVisitor役が受け取ったデータに対して明示的に処理内容を切り替えていた。
しかしChain of Responsibilityパターンの場合はデータがどんなものかを各処理が判断し、適宜処理をするような考え方となっている。
そのためにデータを処理するインターフェースが鎖のように連なっているイメージ。
ChatGPT - Visitor vs Chain of Responsibility
⑮Facade
複雑な一連の処理のAPIを作成して、処理を依頼する側はそのAPIを呼びさえすればよい状態にするパターン。
⑯Mediater
複数の要素の状態によって、それぞれに対して影響を与える場合にやり取りの仲介者を置くパターン。
参考書籍では画面内に以下のものがあるサンプルがあった。
- Guest or Loginを切り替えるラジオボタン
- UserNameを入力するテキストボックス
- Passwordを入力するテキストボックス
- ログインする場合のOKボタン
- ログインをキャンセルするためのキャンセルボタン
各要素の状態によって各々の活性/非活性を切り替えるのに、仲介者を立てて置き、活性/非活性を切りかえるロジックは仲介者のみが知っている状態にして、各要素はそれに従ういう考え方となっている。
⑰Observer
オブジェクトの状態を観察し、変更があった場合に検知できるような実装のパターン。
その変更に対してのイベントを実装したいときなどに有用。
⑱Memento
オブジェクトのスナップショットを取得しておき、そのスナップショットの状態にオブジェクトを復元させることができるパターン。
なんらかの処理の結果、オブジェクトの状態を戻したい場合に使うパターン。
ロジックの組み方次第かもしれないが、基本はオブジェクトが持っているインスタンス変数が復元される使い方となると思われる。
⑲State
システムのふるまいがなにかしらの状態に依存する場合に有用なパターン。
同じ処理を実行する場合でも、実行時の状態によってふるまいを切り替える場合に、状態を管理するためのオブジェクトを生成して依存させるようにする。
参考書籍では昼間と夜間を状態として定義して、サンプルコードのふるまいを昼間状態と夜間状態で切り替える実装をしていた。
⑳Flyweight
インスタンスをできるだけ共有して、無駄にnewしない
ときに使うパターン。
※参考書籍から引用
以下の条件を満たすときに有用かもしれない。
ProtoTypeパターンでは、インスタンスの生成コストは大きいものの、複数のインスタンスを生成する必要がある場合に適用していた。
Flyweightパターンはインスタンス生成自体を最小限にしている。
㉑Proxy
以下、参考書籍からの引用
proxyという単語は「代理人」という意味です。代理人というのは、仕事を行うべき本人の代わり(代理)となる人ですね。
本人でなくてもできるような仕事をまかせるために代理人をたてます。
同じインターフェースを実装し、代理人でも問題の無い処理は代理人に処理をさせて、本人が行うべき処理は本人にさせるという考え方のパターン。
代理人と本人とで分ける必要性については参考書籍に記載があり、個人的には分けた方がわかりやすいと感じた。
㉒Command
命令をオブジェクトとして扱い、オブジェクト経由で処理を実行させたり、オブジェクトを実行履歴として保持しておくパターン。
参考書籍では具体的な命令オブジェクトであるDrawCommand(線を描画する命令)とMacroCommand(複数の命令オブジェクトに一括で命令したり、Undoを実装している)が紹介されていた。
GUIアプリなどでUndoがユースケースとして存在する場合に有用になりそうなパターン。
㉓Interpreter
インタプリタ言語のようなふるまいをさせたいコードを書きたいときに参考にするパターン。
コードをインタプリタに見立てて独自に定義したインプットデータをコードに読み込ませて実行させる。
Pythonなどのインタプリタ言語ではソースコードをインタプリタが解釈して実行しているが、独自定義のデータを解釈するコードを自分で実装する。
感想
もっとサクッと書きたかったのに残業とかで書けない日もあってすごい時間かかった...
ただコードを読んだり考えるのは前よりも上手くなった気がするので結果書いて良かったです。
Alembicを使ってModelとテーブル定義を紐づけて管理する
- テーブル定義を更新するたびにALTER文を書くのツライ...!
- Alembicとは
- なにができるか
- ディレクトリ構成
- 環境作成
- ここからが本題
- Alembic initを実行する
- 生成ファイルを確認する
- SQLAlchemyのBase情報を実装する
- Modelを実装
- env.pyを編集
- リビジョンファイルを生成する
- テーブル情報を更新する
- autogenerateで検知してくれない変更
- サンプルコード
テーブル定義を更新するたびにALTER文を書くのツライ...!
というのがきっかけで、Alembicについて使い方を最低限ですが調べてみました。
お仕事で
- flask
- SQLAlchemy
- SQLServer
な感じでWebアプリを作成しているのですが、新規開発ということもあってテーブル定義の修正が多いです。
ある程度は仕方ないと思いつつ、カラムを一つ追加するたびに
- CREATE TABLE文(本番作成や新しく環境を作る人向け)
- ALTER文(既存のローカルDBや開発環境向け)
- SQLAlchemyのModel定義
- その他諸々(プロジェクト固有の管理ファイルなど)
を更新する必要があり、テーブル定義を修正する回数が多いのも相まって結構大変でした。
なので今後は可能だったらSQLAlchemyを入れるなら、Model定義をテーブル定義を紐づけて管理できる仕組みを使いたいと思い、存在は知っていたものの触れずにいたAlembicを少し動かして調べてみました。
読んでくれた人の参考になればうれしいです。
Alembicとは
Alembic is a lightweight database migration tool for usage with the SQLAlchemy Database Toolkit for Python.
訳)Alembic は SQLAlchemy Database Toolkit for Python 用の軽量なデータベース移行ツールです。
なにができるか
SQLAlchemyを使用するために定義する各テーブルのModel定義と、RDBのテーブル定義とを一貫して作成や変更ができるようになります。
SQLAlchemyを使うとアプリのコード中にDML(Data Manipulation Language)を書かなくてもRDBとのCRUD処理をできるようになりますが、Alembicを使うことでテーブルを作成するためのDDL(Data Definition Language)も書かなくてよくなります*1。
ディレクトリ構成
動作確認がてら書いたコードのため、models配下のファイルは結構テキトーです。
. ├── .devcontainer │ ├── devcontainer.json ├── DB │ ├── DATA │ ├── LOG │ └── secrets ├── Dockerfile ├── alembic │ ├── README │ ├── env.py │ ├── script.py.mako │ └── versions │ ├── 2024_07_24_2100-f2932c930d16_init_create_table.py ├── alembic.ini ├── app │ ├── db_setting │ │ └── db_base.py │ ├── main.py │ └── models │ ├── person.py │ ├── todo.py │ ├── user.py │ └── user2.py ├── compose.yml └── requirements.txt
各ディレクトリについて簡単に説明します。
- DB:SQLServerの各種データファイルを格納
- alembic:alembic init をしたときに作成されるディレクトリ
- app:アプリディレクトリ
- app/db_setting:SQLAlchemyからDBにアクセスするための設定情報などを格納
環境作成
動作環境は以下となっています。今回もDev Containerを使ってDocker環境上に開発環境を作成しています。
- Debian GNU/Linux 12
- Python 3.11.9
- Microsoft SQL Server 2019 Express Edition
アプリとDBのコンテナをcompose.ymlで定義
compose.ymlに以下の記述をします。
services:
almebic-app:
container_name: almebic-app
build: ./
tty: true
volumes:
- ./:/workspace
working_dir: /workspace
mssql:
container_name: almebic-mssql
image: mcr.microsoft.com/mssql/server:2019-latest
ports:
- 1434:1433
environment:
- ACCEPT_EULA=Y
- MSSQL_SA_PASSWORD=saPassword1234
- MSSQL_PID=Express
- MSSQL_LCID=1041
- MSSQL_COLLATION=Japanese_CI_AS
volumes:
- ./DB/DATA:/var/opt/mssql/data
- ./DB/LOG:/var/opt/mssql/log
- ./DB/secrets:/var/opt/mssql/secrets
services配下のalmebic-appでは、アプリ用のコンテナを定義しています。
mssqlでDB(SQLServer)用のコンテナを定義しています。
Docerkfileでアプリコンテナビルド時の設定を追加する
Dockerfileに以下を書いて保存します。
FROM python:3.11 RUN apt-get update RUN curl https://packages.microsoft.com/keys/microsoft.asc | apt-key add - && curl https://packages.microsoft.com/config/debian/12/prod.list > /etc/apt/sources.list.d/mssql-release.list RUN curl -sSL https://packages.microsoft.com/keys/microsoft.asc | gpg --dearmor > /usr/share/keyrings/msprod.gpg RUN echo "deb [arch=amd64,arm64,ppc64el,s390x signed-by=/usr/share/keyrings/msprod.gpg] https://packages.microsoft.com/debian/12/prod bookworm main" | tee /etc/apt/sources.list.d/mssql-release.list RUN apt-get update RUN ACCEPT_EULA=Y apt-get install -y msodbcsql17 RUN apt-get install -y unixodbc-dev RUN pip install pyodbc WORKDIR /workspace COPY ./requirements.txt /workspace/ RUN pip install --no-cache-dir -r requirements.txt
上記のcurlしている箇所は、AlembicからSQLAlchemyのライブラリを呼ぶのに、MSのパッケージのインストールをする必要があり、公式ドキュメントやChatGTPを使いながらどうにかAlembicを動かせるようになりました(結構時間かかった)。
そのうちcurlでなにをしているかの詳細も調べて記事にしたいです。
devcontainer.jsonとrequirements.txtを編集
devcontainer.json
{ "name": "almebic_learn", "service": "almebic-app", "workspaceFolder": "/workspace", "dockerComposeFile": "../compose.yml", "customizations": { "vscode": { "extensions": [ "ms-python.python" ] } } }
requirements.txt
alembic==1.13.2 greenlet==3.0.3 Mako==1.3.5 MarkupSafe==2.1.5 pyodbc==5.1.0 SQLAlchemy==2.0.31 typing_extensions==4.12.2
requirements.txtはコンテナを立ち上げて、一つ一つ必要なものを手動でインストールしてからpip freezeさせつつ書いていきました。
Dev Containerを立ち上げてアプリとDBのコンテナが動いているか確認する
Dev Container自体はvscodeでSHIFT+Ctrl+Pで簡単に起動します。
このあたりを実行すればOKです。

起動が成功したら、docker containerコマンドで確認。

ここからが本題
いままではAlembicを使うための準備でした。
以降でAlembicを実際に使っていきます。
Alembic initを実行する
Alembicを使うには、初期化を行う必要があります。
コマンドは以下です。
alembic init alembic
2つ目の"alembic"はalembicが生成する各種ファイルが格納されるディレクトリ名称を指定しています。
生成ファイルを確認する
alembic.ini
alembicによって管理したいDBの接続情報の設定や、生成するリビジョンファイルの命名規則を指定するなどのことができます。
以下で接続情報の設定を行います。今回はSQLServerですが、使うDBによってドライバーは変わることになります。
sqlalchemy.url = mssql+pyodbc://sa:saPassword1234@172.22.0.3:1433/alembic-learn?driver=ODBC+Driver+17+for+SQL+Server
また、ファイル名の命名規則は初期化直後はコメントアウトされているのですが、コメントを解除するだけでも問題ないので適用するのがおすすめです。
file_template = %%(year)d_%%(month).2d_%%(day).2d_%%(hour).2d%%(minute).2d-%%(rev)s_%%(slug)s
こんな風にリビジョンファイルに日付+リビジョンID+リビジョンファイル生成時のコメントという形式でファイル名になります。
※リビジョンファイルの生成については後述します。

env.py
env.pyではalembicが実行されるたびに実行されるスクリプトが書いてあります。
各Modelクラスが継承しているのと同じBase.metadataを利用することで、Modelの情報を取得してDBマイグレーション用のリビジョンファイルを作成してくれます。
編集内容は後述します。
script.py.mako
リビジョンファイルを生成するときのテンプレートファイルのようです。
これを編集することで以降で生成されるリビジョンファイルに対して変更を加えることができるようですが、あまり編集することはないかもしれません。
README
どのような環境で migration 環境を作成したか記述してある(らしい)
SQLAlchemyのBase情報を実装する
app/db_setting/db_base.pyにたいして、以下を実装します。
from sqlalchemy.ext.declarative import declarative_base from sqlalchemy import MetaData, create_engine from sqlalchemy.orm import sessionmaker # 統一されたMetaDataオブジェクトを作成 metadata = MetaData() Base = declarative_base(metadata=metadata)
Metadata()をして明示的にmetadataを作成しているのは一応念のためやったようなもので、しなくても問題ありません。
ただ、alembicに渡すModelでは同じmetadataを持つBaseを継承している必要があります。
Modelを実装
各Modelは先ほど実装したBaseを継承させてクラスを作成します。
app/models/todo.py
from sqlalchemy import Column, Integer, String, DateTime, create_engine
from app.db_setting.db_base import Base
class Todo(Base):
__tablename__ = 'todo'
id = Column(Integer, primary_key=True)
description = Column(String)
deadline = Column(DateTime)
status = Column(String)
app/models/person.py
from sqlalchemy import Column, Integer, String, NVARCHAR
from app.db_setting.db_base import Base
class Person(Base):
__tablename__ = 'PERSON'
id = Column(Integer, primary_key=True)
NAME = Column(NVARCHAR(128))
WEIGHT = Column(Integer)
HIGH = Column(Integer)
AGE = Column(Integer)
Personクラスでは文字列の型指定を"NVARCHAR"にしています。
Stringを指定するとデフォルトでVARCHARとしてalembicがカラムを作成してしまうようなので。
env.pyを編集
alembicではrevisionファイルを生成し、それをDBに適用することでテーブル情報の更新ができます。
revisionファイルでは各テーブルの操作内容が記録されていくのですが、env.pyはrevisionファイルを生成するために必要なスクリプトです。
上記を行うために、alembic init コマンドで生成されたenv.pyに2点の情報を加えてあげる必要があります。
- 各Modelが継承しているBaseオブジェクト
- Alembicが変更を監視したいModel情報(Importします)
env.py
from app.db_setting.db_base import Base from app.models.todo import Todo from app.models.person import Person target_metadata = Base.metadata
本当はImport文をすべてのModel分書くのはしたくなかったのですが、いろいろ試したもののImport文をきちんと書くのが一番挙動が安定しました。
※このあたり、上手く言った方法があれば知りたい...
リビジョンファイルを生成する
上記まででAlembicでリビジョンファイルを生成する準備ができています。
リビジョンファイルはModel情報の変更を検知し、DBに適用するためのコードが記載されています。
環境さえ作ってしまえば、その後の運用は
1. リビジョンファイルを作成
2. リビジョンファイルをつかってテーブル情報を更新
という2アクションで済むようになります。
リビジョンファイルを生成するコマンドは以下です。
alembic revision --autogenerate -m "<任意のメッセージ>"
または
alembic revision -m "<任意のメッセージ>"
--autogenerateオプションを付けることで、Alembicが自動でModelの変更を検知してくれるので、基本的にはautogenerateするのが良いと思います。
しかし、Alembicが検知できない変更が一部であるようで、実際に生成されたリビジョンファイルを見て検知されていない変更があった場合には、手作業でリビジョンファイルを修正することもあります。
--autogenerateオプションを付けないパターンはあまりまだイメージが湧かないですが...
実際に生成されるファイルは以下のようになります。
"""Recreate Person table Revision ID: 00b30bc8319b Revises: 8ccd3fdbbd2a Create Date: 2024-08-09 20:41:41.647385 """ from typing import Sequence, Union from alembic import op import sqlalchemy as sa # revision identifiers, used by Alembic. revision: str = '00b30bc8319b' down_revision: Union[str, None] = '8ccd3fdbbd2a' branch_labels: Union[str, Sequence[str], None] = None depends_on: Union[str, Sequence[str], None] = None def upgrade() -> None: # ### commands auto generated by Alembic - please adjust! ### op.create_table('PERSON', sa.Column('id', sa.Integer(), nullable=False), sa.Column('NAME', sa.NVARCHAR(length=128), nullable=True), sa.Column('WEIGHT', sa.Integer(), nullable=True), sa.Column('HIGH', sa.Integer(), nullable=True), sa.Column('AGE', sa.Integer(), nullable=True), sa.PrimaryKeyConstraint('id') ) # ### end Alembic commands ### def downgrade() -> None: # ### commands auto generated by Alembic - please adjust! ### op.drop_table('PERSON') # ### end Alembic commands ###
def upgrade()にリビジョンファイルを適用したらどういうテーブル操作をするかが記載されています。
def downgrade()にはリビジョンファイルを使って、ダウングレードしたらどういう操作をするかが記載されています。
downgradeについては挙動は確認していません。
ダウングレードする操作も用意されているんだなという程度に覚えておこうと思います。
テーブル情報を更新する
先ほどの操作で生成されたリビジョンを使って、テーブルを作成します。
コマンドは以下を使ってアップグレードしていきます。
# 最新のリビジョンまでマイグレーション alembic upgrade head # 次のリビジョンへマイグレーション alembic upgrade +1
upgradeコマンドを実行し、成功すると以下のようなメッセージが表示されます。
root@f3147b745f82:/workspace# alembic upgrade head INFO [alembic.runtime.migration] Context impl MSSQLImpl. INFO [alembic.runtime.migration] Will assume transactional DDL. INFO [alembic.runtime.migration] Running upgrade 835fb960607e -> 321bb84fc5cc, Recreate pserson table.
autogenerateで検知してくれない変更
以下を参照してください。
サンプルコード
サンプルコードといっても、自分が確認のために書いていたコードなので内容はお察しです。
ストアドでIDの空き番を探す
クエリの動作環境
- OS:20.04.4 LTS (Focal Fossa)
- SQLServer:Microsoft SQL Server 2022 (RC0) - 16.0.900.3 (X64)
Aug 10 2022 03:18:41
Copyright (C) 2022 Microsoft Corporation
Developer Edition (64-bit) on Linux (Ubuntu 20.04.4 LTS)
※Dockerで動かしています
ストアド作成用のクエリ
CREATE PROCEDURE GetIDGaps AS BEGIN -- Declare table variables to hold gaps and max value DECLARE @Gaps TABLE (StartID INT, EndID INT); -- Find gaps in the ID sequence ;WITH CTE AS ( SELECT BusinessEntityID, ROW_NUMBER() OVER (ORDER BY BusinessEntityID) AS RowNum FROM Person.Person ) INSERT INTO @Gaps (StartID, EndID) SELECT t1.BusinessEntityID + 1 AS StartID, t2.BusinessEntityID - 1 AS EndID FROM CTE t1 LEFT JOIN CTE t2 ON t1.RowNum = t2.RowNum - 1 WHERE t2.BusinessEntityID - t1.BusinessEntityID > 1; -- Select the gaps SELECT StartID, EndID FROM @Gaps; END;
使用しているデータ
AdventureworksというMSのサンプルデータを利用しています。
正確には、Adventureworksのデータを利用しているDockerイメージを使わせてもらっています。
こちらのブログで紹介されているDockerイメージをビルドしました。
ストアドを作成する前に、ストアドが実行されたときの結果を先に確認
CREATE PROCEDUREしないように、実際に動作する部分のクエリを選択してSSMSで実行します。
左は実際の空き番の開始IDと終了ID、右は特に条件を指定しないテーブルの取得結果です。

BusinessEntityIDが歯抜けになっている部分の値と、ストアドの結果が一致しています。
あとはCREATE PROCEDUREから実行すればストアドが作成できますね。
感想?的な
ストアドを書くことが最近はめっぽう減っていて、ちょっと書き方というか雰囲気を思い出したいなと思い、書いてみました。
ストアドどうこうよりも、Adventureworksが入ったSQLServerをDockerでインストールしてすぐに使えるのが感動してしまった...w
10歳からのプロジェクトマネジメント感想文
10歳からのプロジェクトマネジメントを読んでみた
10歳からのプロジェクトマネジメント(以降、本書とします)が以前Xで話題になっていて、自分が今後はPMになりたいと思っているので良い入門書になるかなと思い読んでみました。
(話題の火付け役はこのポストだった気がする)
ねぇ、待ってマジおもしろすぎる!!
— たんたん @ 空前絶後のPMO🌸🌹💐 (@pmo_tantan) 2024年4月25日
本届いたからパラパラ読んだだけだけど、これプロジェクトマネジメントについて地獄みたいに分かりやすく書かれてる!!
これができない中年プロジェクトリーダーを見てきてるんだよ!!読んでくれよこれ!!語りてぇ!! pic.twitter.com/g1gEHHVpP1
本書全体の感想
プロジェクトマネジメント(以降、プロマネとします)で求められる必須なスキルというか、計画の立て方を体系立てて説明してくれています。
説明も対象読者を10歳から想定しているためか、わかりやすい言葉が多かったです(なので具体例はむしろ飛ばし読みしがちでしたが)。
漫画の部分では、内容への導入として解決したい課題や悩みを描いていて、それに対するアンサーとしてプロマネではこういう風にアプローチするんだよ、といった感じで全体が進んでいきます。
全体を通してなるほどと思えましたし、プロジェクトでよく使われる言葉の定義を改めて理解できて良かったです。
自分が考えたこと
一応ITエンジニアの端くれとして、いくつかのプロジェクトに参画させていただいてきてますが、プロジェクトによって各計画段階での計画書の呼び名って結構ブレブレな気がする。 本書では
- WEB:達成したい目標を作業が実行しやすいサイズまで分解してあらわしたもの
- ガントチャート:どんなタスクがあって「だれが」「いつ」やるかなどを管理できるもの
として紹介されています。
でも結構WBSと評して、そこに作業期限も一緒にくっつけてタスクの期限として管理しているプロジェクトあった気がする。
それ自体は結局ガントチャートがWBSを元に作られることを思えばおかしいことではないけど、各資料の位置づけをプロマネ担当者がしっかり区別しないと、WBSの修正や更新の時に何を管理している資料なのかわかりにくくなってしまっていたんじゃないかとか思いました。
また、きちんうまくいっているウォーターフォールならWBSやガントチャートを触るのはプロマネ担当者だけで済むけど、なし崩し的にアジャイル風になっている状態だと必要なタスクが追加になったときに、WBSに個々の作業者が追加OKとしている場合、WBSの書き方や粒度に対して一定のポリシーを作っておかないと
結局それを資料としてみたと時にいまいちな資料になってしまいそうな気がしました。
※なし崩し的にアジャイル、というのは自分がちゃんとした?アジャイルを経験したことがないからです
プロジェクトにおいてガントチャートとかWBS、タスクとかの用語って一般的なものとして共通認識がある前提で進められることが多いけど、まずはそのあたりの用語では何を表すのかをはっきりするところからプロマネをスタートするのが良いのではと思いました。
基本設計書(お客さんがみてシステムの動きがわかるやつとします)で、用語の定義を最初に記載することってあると思いますが、そういう感じでプロマネ運用上で必要な言葉の定義を各メンバーにも伝わるように文書化しておいた方が、各種管理用の資料の意図がより伝わりやすい気がする。
少なくとも自分は、何を管理するための資料と記載がある方が、それに合わせた粒度で資料の更新や報告を上げやすいと思います。
(もちろんよりフランクな相談をする場もあったうえで)
最後に
本書はプロマネの基本を押さえるのにとてもよさそうだと思いました。
紹介されていた内容を元に、自分のタスクを管理するところからやっていこうかと思います。
Nginxで初めてのプロキシ設定
- この記事で紹介すること
- OSなど環境
- nginxの設定ファイル
- プロキシ実行のための環境(構成図)
- includeファイルの削除(つまづき①)
- nginx.confの編集
- そのほかのつまづきポイント
- 実際に動作したのは見たが...
- 参考
- 感想
この記事で紹介すること
- nginxの設定ファイルの書き方
- proxy_pathを利用した、プロキシ設定方法
- 上記をするまでにつまづいたところ
などを紹介する予定です。
OSなど環境
nginxの設定ファイル
nginxには主に以下のファイルがインストール時点で存在しています。
- /etc/nginx/nginx.conf
- /etc/nginx/sites-enabled/default(Ubuntuでapt installするといる)
- /etc/nginx/conf.d/default.conf(dockerのnginxイメージだとこっちがデフォルトファイル)
基本的には/etc/nginx/nginx.confに記載されている設定内容で実行されるのですが、nginx.confにinclude句を付けることで、
そのほかのディレクトリ配下に存在する設定ファイルを読み取って利用することもできます。
こういうやつですね。
include /etc/nginx/conf.d/*.conf; include /etc/nginx/sites-enabled/*;
Ubuntuでnginxをインストールしたときのnginx.confを載せます(コメント行のいくつかは削除しました)。
user www-data;
worker_processes auto;
pid /run/nginx.pid;
include /etc/nginx/modules-enabled/*.conf;
events {
worker_connections 768;
# multi_accept on;
}
http {
##
# Basic Settings
##
sendfile on;
tcp_nopush on;
tcp_nodelay on;
keepalive_timeout 65;
types_hash_max_size 2048;
include /etc/nginx/mime.types;
default_type application/octet-stream;
##
# SSL Settings
##
ssl_protocols TLSv1 TLSv1.1 TLSv1.2 TLSv1.3; # Dropping SSLv3, ref: POODLE
ssl_prefer_server_ciphers on;
##
# Logging Settings
##
access_log /var/log/nginx/access.log;
error_log /var/log/nginx/error.log;
##
# Gzip Settings
##
gzip on;
##
# Virtual Host Configs
##
include /etc/nginx/conf.d/*.conf;
include /etc/nginx/sites-enabled/*;
}
すべては説明するのは大変なので、簡単に設定ファイルの見方をご紹介します。
スペース区切りでkey value形式で、最後に;(セミコロン)で終わっているものを単純ディレクティブと呼びます。 以下でしたらアクセスログのパスや、含めたい設定ファイルのパスを指定しています。
access_log /var/log/nginx/access.log; include /etc/nginx/conf.d/*.conf;
{}(波かっこ)で括られている範囲はブロックディレクティブと呼びます。
ブロックディレクティブは複数の単純ディレクティブを含めることができます。
このブロックディレクティブ内に、nginxにしてもらいたい仕事の種類や挙動を単純ディレクティブを使って記載していくイメージです。
※仕事の種類とは、Webサーバーで合ったりロードバランサー、(リバース)プロキシサーバーなどのことを指しています。
http {
##
# Logging Settings
##
access_log /var/log/nginx/access.log;
error_log /var/log/nginx/error.log;
##
# Virtual Host Configs
##
include /etc/nginx/conf.d/*.conf;
include /etc/nginx/sites-enabled/*;
}
プロキシ実行のための環境(構成図)

図のProxyサーバーへのHTTPリクエストを、Webサーバーにプロキシする設定を入れたいと思います。
includeファイルの削除(つまづき①)
今回はProxyの設定行うため、httpのブロックディレクティブを編集していきます。
実は最初の引っ掛かりポイントとして、デフォルトファイルをincludeしていると、そちらのserverディレクティブとnginx.confのserverディレクティブが競合してしまい、nginxを起動することができません。
そのため
- includeディレクティブで指定されているパスのファイルを削除
- includeディレクティブを削除
のどちらかを行います。
今回はファイルを削除しました。
nginx.confの編集
/etc/nginx/nginx.confのhttpディレクティブ内に以下を追記します。
location / {
# 最低限proxy_passだけでも動きます
proxy_pass http://10.1.0.20;
proxy_set_header Host $host;
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
proxy_set_header X-Forwarded-Proto $scheme;
}
locationで/を指定しているのは、このProxyサーバーへのHTTPリクエストをすべて10.1.0.20へプロキシさせるために指定しています。
(そのほかのヘッダに関するものは割愛します)
そのほかのつまづきポイント
ファイルの権限不足
実行したときに以下のエラーが出ました。
nginx: [alert] could not open error log file: open() "/var/log/nginx/error.log" failed (13: Permission denied)
読んだらわかるのですが、nginxがエラーログファイルへの権限が不足していました。
nginxがファイル操作をするときのユーザーはwww-dataなので、以下のコマンドでファイルの所有者とパーミッションを設定しました。
sudo chown -R www-data:www-data /var/log/nginx sudo chmod -R 755 /var/log/nginx:[
特権ユーザー権限で実行しなさい警告
2024/05/22 19:48:45 [warn] 1212#1212: the "user" directive makes sense only if the master process runs with super-user privileges, ignored in /etc/nginx/nginx.conf:1
特権ユーザーの権限で実行しないとuserディレクティブが無視されてしまうらしいので、以下で再起動。
sudo nginx -s reload
実際に動作したのは見たが...
それぞれのマシンのIPアドレスがどうで、表示されているindex.htmlがどちらのだからとかを説明すると万一出しちゃいけない情報を出すとまずいので、検証は自分ではできたということさせてください。
参考
感想
ロードバランサーやキャッシュサーバー(CDNサーバー)の勉強をしたくて本を読み始めて、自分で作ってみたくでnginxを触ったのですが、案外confファイルの設定の仕方がわかりやすくて意外でした。
ただ、nginxはやれることが多い分ドキュメントも大量に合って、さすがに全部は読めませんでした。
初めの一歩ということでプロキシ設定を入れてみたけど、ロードバランサーとキャッシュサーバーも作ってみたいなとは思っています。
マネジメント志向なのでそれ系の本も読まないとなのですが...
時間足りないなー。
Python loggingの基本的な使い方を抑える
この記事で説明すること
Pythonのloggingを使ったログ処理について、業務上扱うのに先に抑えておくべきだったなと思ったことを紹介します。
先に結論的な
- loggerにはsetLevelがあり、logger毎に扱うログのレベルを設定可能
- 各loggerにはhandlerがありhandlerごとにログの出力先の設定や、handler自体にもsetLevelを設定可能
- ルートロガーは特別なloggerで、デフォルトで使用すると以下の設定となる
- loggerのsetLevel:WARNING
- handler:lastResort(実質のところStreamHandler)
- handlerの出力先:標準エラー出力
- handlerのsetLevel:WARNING
loggerについて
Pythonのloggingモジュールでは、以下のようにしてlogger(ロガー、ログを出力してくれるもの)インスタンスを生成します。
生成したインスタンスを利用し、infoやerrorなどのログを出力することができます。
import logging logger = logging.getLogger() logger.info("infomation message") logger.error("error message")
上記のような使い方でも、個人開発でローカル環境ならそこまで問題ないかもしれません。
ただ、上記例だとinfo()でログが表示されない状態となっています。
なぜそのようになっているかというと、
上記ではルートロガーを生成しており、ルートロガーのデフォルトのsetLevelがWARNINGだからです。
logger自体のLevel
loggerにはLevelという、インスタンス変数があります。
インスタンス変数なので、logger毎に設定が可能です。
先ほどの例でいうと
import logging
logger = logging.getLogger()
logger.setLevel(logging.INFO)
とすることでそのloggerが扱うLevelを設定することができます。
ここでいうLevelとは、そのloggerが扱うログの重要度のことであり、設定したLevel未満のログはloggerによって無視されます。
Levelは以下があります(公式より画像引用)。
 たとえば、
たとえば、
logger.setLevel(logging.INFO)
logger.debug("debug message")
の場合には、loggerのLevel(INFO)よりも、DEBUGのLevelが低いため、上記の"debug message"はloggerが無視し、処理しないことになります。
NOT SETだったら全部のLevelが処理されるはず
先述の
import logging logger = logging.getLogger() logger.info("infomation message") logger.error("error message")
ではinfo()でログが表示されない状態と記載しました。
上記のコードであればLevelを指定していないので、NOT SETとして設定されていそうな気がしますよね。
しかし、例によってルートロガーは特別にLevelのデフォルト値がWARNINGになっているために、loggerがINFOレベルのログを無視していたのでした。
loggerには名前空間があり、名前空間ごとにLevelを設定できる
loggerには名前空間があります。
名前空間はある範囲での名前が重複せずに、一意の名前であるように識別するものです。
例えば以下の場合だと、各々3つの名前空間に対してlogger自身のLevelも設定できますし、logger毎にhandlerとhandleのLevelも設定可能です。
- sample
- sample.child
- sample.child.grandchild
名前空間では . (ドット)で親子関係を表現できます。上記の例であればsampleが親、childが子、grandchildが孫となります。
子ロガーでログ出力の際、handlerが設定されていなかった場合には親ロガーへログ処理が委譲されます(デフォルト設定のままなら)。
例ではgrandchildロガーがhandlerを持っていなければ、childに委譲され、さらになければsampleでログ処理が行わます。
さらにsampleにもhandlerがなければ、最終的にルートロガーに委譲され処理が行われます。
ただし明確な理由がなければ、基本的にルートロガーのみににLevelやhandlerを設定を設定し、子ロガーでは処理をルートロガーに委譲する使い方でも良いと思います。
handlerとは
handler(ハンドラ、ハンドラー)とは、実際のログ処理を
- どこに出力するか
- handler自身ではどのLevelを扱うか
などについて設定できます。
handlerの種類
handlerにはいくつかの種類があり、それによってログの出力先を変更できます。 いくつか例を挙げると
- StreamHandle
- FileHandler
- ディスク上のファイルへ出力
- HTTPHandler
- URLを指定したWebサーバー上でPOSTなどで出力
などがあります(記事を書くにあたって調べたら、他にもたくさんあって面白かったです)。
handlerにもLevelがある
loggerのLevel同様、handlerにもLevelを設定できます。
考え方的にはlogger自体に設定するものと一緒です。
各loggerとhandlerの処理順序
loggerとhandlerのそれぞれにLevelを設定できます。
しかしそれぞれのLevelが一致していない場合、どちらが優先されるのでしょうか。
答えはloggerが先に判定し、そのあとにhandlerが最終的に処理するかどうかを決めます。
例えば以下の場合、loggerのLevelよりもhandlerのLevelが高いため、結果的にDEBUGログを出力できません。
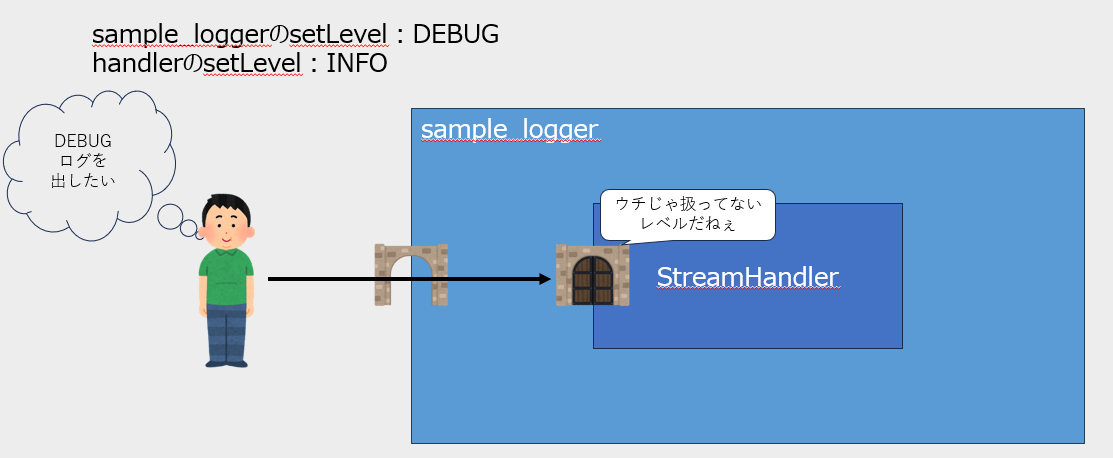
また、loggerのレベル未満のログはhandlerに届くことすらありません。
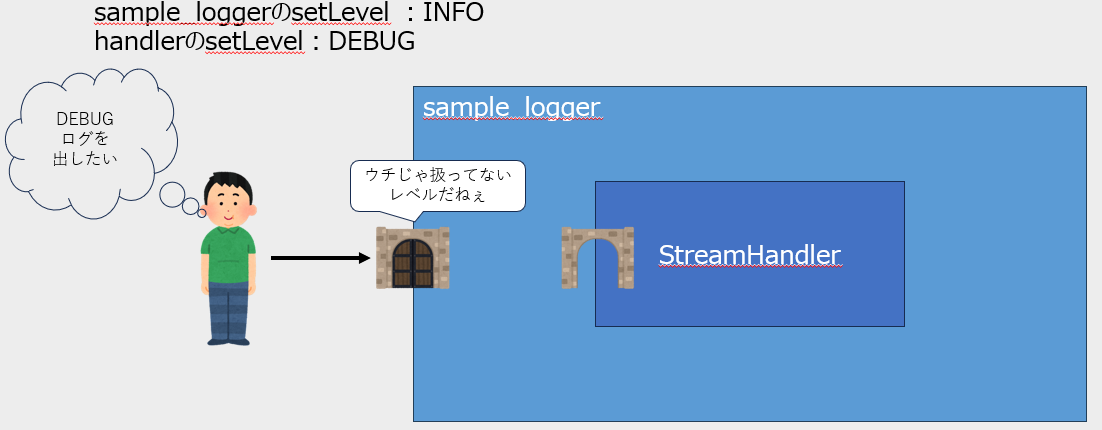
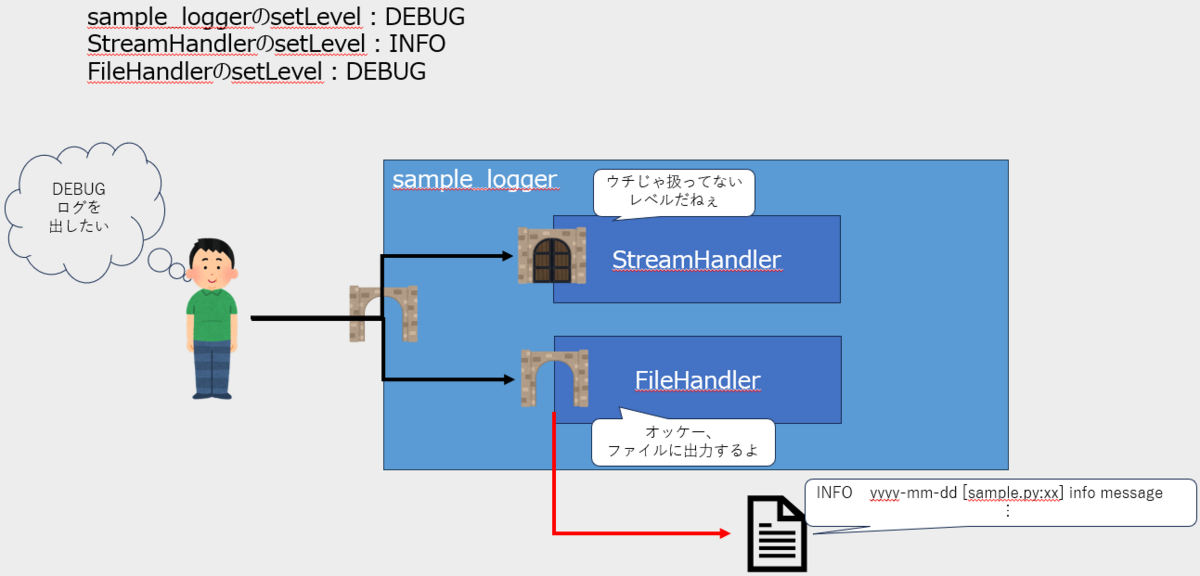
handlerは複数設定することもできるため、loggerが扱うLevelの範囲であれば、
以下のようなこともできます。
他にもFormatterとかあるけど
ここまでの内容ですでに3200文字を超えているため、この記事は一旦ここまでにします。
logger自体のLevelとhandlerの使い方がわかれば、まずは最低限意図したログを出せるようになるかなと思います。
余談(ほんとは一番言いたかったこと)
ルートロガーをデフォルトのまま使っていたせいで、Azure App Serviceの監視をしているLogAnalytics上でINFOログが全部ERRORで出力していたことが今回の記事のきっかけでした。
そもそもルートロガーをそのまま使うなよとかありそうですが、今回良い勉強になったのでヨシ!!!
pip freezeの出力結果をWindowsとLinuxで比べてみた
行ったこと
Windows環境とLinux(Debian)環境で同じパッケージをインストールしている状態で、pip freezeしたら本当に環境ごとに出力結果が異なるか軽く動かしています。
AzureのKey Vaultを実行するパッケージをインストールしたときに、どのような違いが出るかで確認しました。
背景
- 業務でWindowsとLinuxの環境差異でpip install -r requirements.txtがエラーになることが多い
- Windows環境で出力したrequirements.txtをLinux環境で使うのがそもそも良くないらしい
環境
Windows
OS:Windows 11 Pro 23H2
Python:3.9.13
pip:24.0
Linux
OS:Debian GNU/Linux 11 (bullseye)
Python:3.9.13
pip:24.0
各環境上でのパッケージインストール
各環境上で以下を実行します。
pip install azure-identity pip install azure-keyvault-secrets
Windows上では仮想環境を利用していますが、Linux環境では今回はDockerコンテナを利用しているため、仮想環境は利用せずに、コンテナにそのままパッケージをインストールしました。
パッケージのインストールなどはこちらを参考にしています。
pip freezeの実行
それぞれの環境で以下を実行します。
pip freeze > requirements.txt
結果を比較
Winmergeを使い、確認できた結果が以下でした。
左:Windows
右:Linux
 pywin32というパッケージがWindows環境でのみrequirements.txtに出力されているのがわかります。
pywin32というパッケージがWindows環境でのみrequirements.txtに出力されているのがわかります。
これはAzureリソースへアクセスするためにWindows環境では必要ということなんだと思われます。
(pycparserのバージョンが異なっていますが、今回は無視します)
最後に
Dockerコンテナを利用するなどして、開発環境や本番環境の環境差異をなくすことで、今後インストールパッケージの違いなどからくるエラーをなくしていきたいですね。
WindowsとLinuxでpycparserのバージョンが異なってしましたが、そもそも開発自体もDockerで本番とほぼ同じ環境を用意すれば、環境の違いによるエラーは防げるだろうと思います。
当たり前だろうと思われる方も多かったと思いますが、ここまで読んでくださってありがとうございます。